


NVIDIA's Earth-2 Integration into TrueOcean
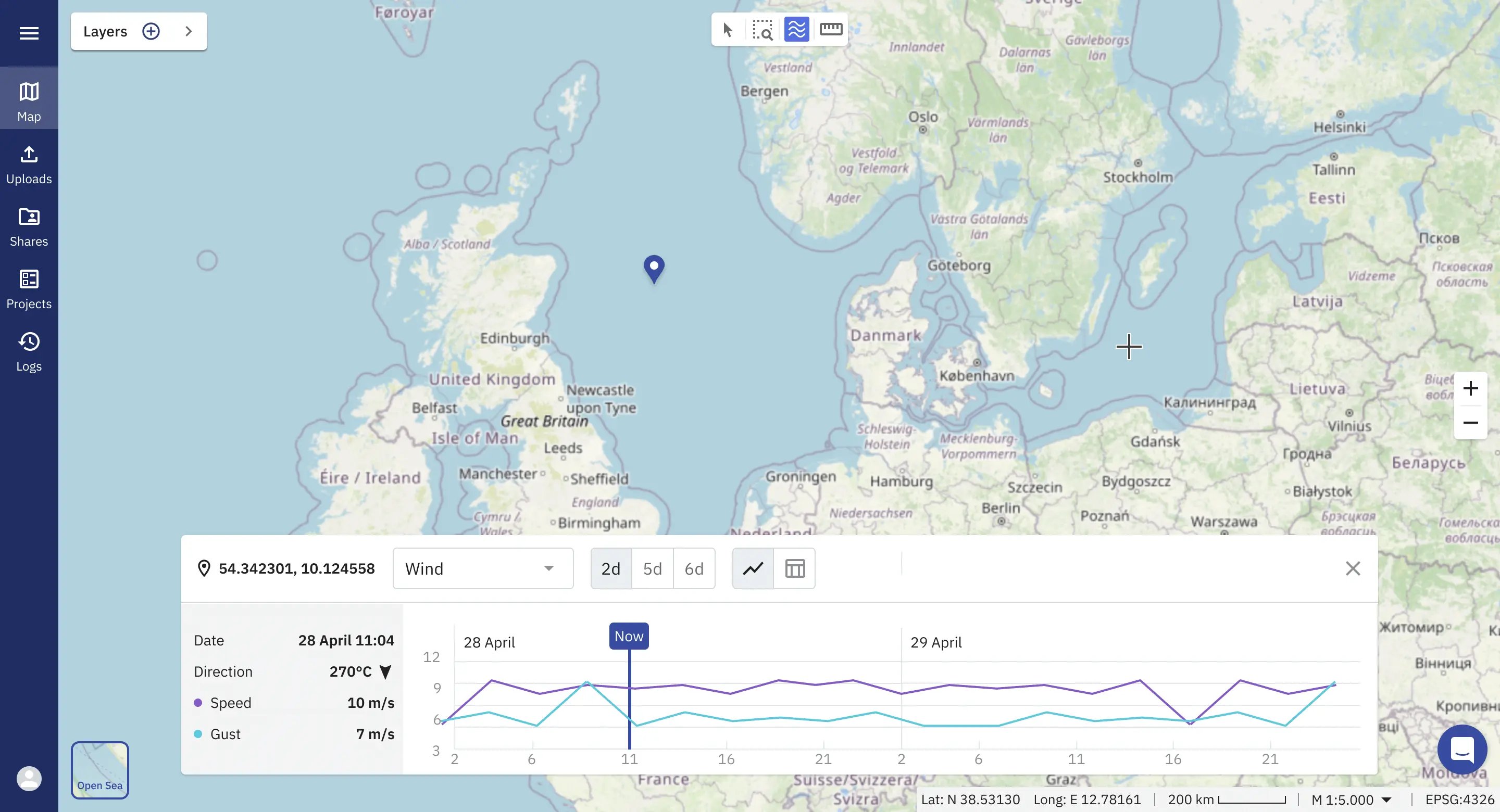
Autonomous systems, including ships, surface, and underwater vehicles, will revolutionise our understanding of the still largely unknown oceans. The future integration of NVIDIA's Earth-2 digital twin technology into the TrueOcean platform will significantly advance intelligent operational planning, system management, and risk assessment for complex autonomous data collection. Our goal is to optimise efficiency and mitigate risk using the best available information on weather, historical conditions, sea state, and the effects of climate change.
Learn more about how AI and Accelerated Computing will transform ocean data processing in our latest blue paper, which explores these advances in TrueOcean’s new module, Zeus, available from the 3rd quarter of 2024.


Enables Information Comprehension
The platform facilitates better understanding of data, even for non-experts, reducing the risk of knowledge and information loss. This ensures that all involved parties can make informed decisions based on a comprehensive understanding of the data.

Informed Decision-Making and Risk Mitigation
With faster access to information, the TrueOcean platform allows for better data quality control and analysis. This enables informed decision-making and effective risk mitigation strategies, reducing uncertainties and improving project outcomes.

Enhanced Project Efficiency and Cost Reduction
By digitalising data processes, the platform automates various steps, saving valuable resources and reducing manual efforts. Standardising processes eliminates inefficiencies, leading to enhanced project efficiency and cost reduction.

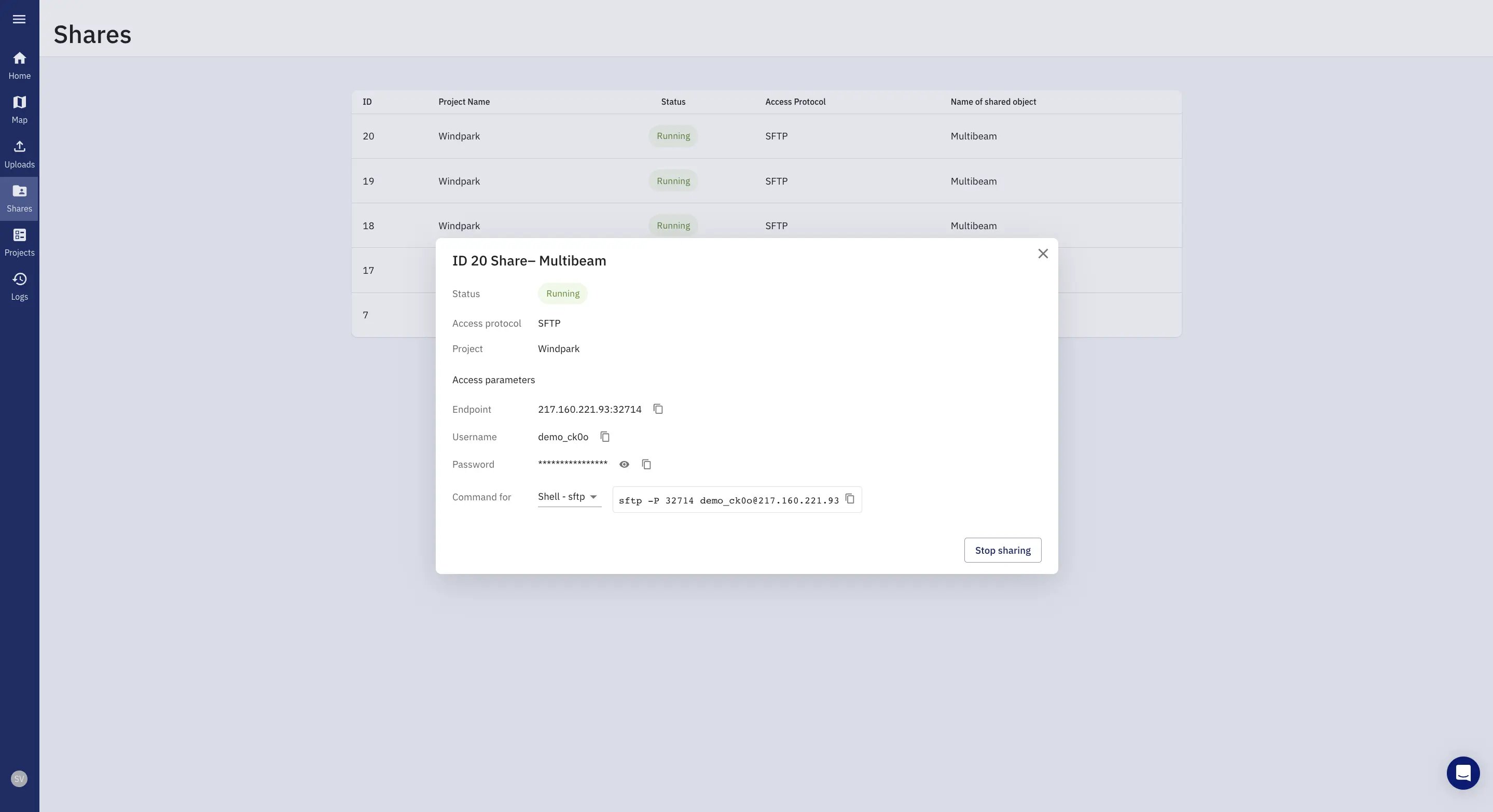
Secure Data Storage and Protection
The TrueOcean platform prioritises the secure storage and protection of data. By maintaining control over valuable data, users can safeguard their investment and preserve a competitive advantage. This is particularly crucial in offshore wind projects where acquired data can hold significant value.
Optimise your Ocean Data Management with TrueOcean's White Paper


Cloud Agnostic
TrueOcean can be operated on all clouds (public, private, hybrid). Only a managed Kubernetes cluster is required. We do not use any vendor-specific applications.
Scalability
Prepared for fully scalable Big Data workflows for spatial operations on raster, vector, and point data provide speed on-demand.
Interoperability
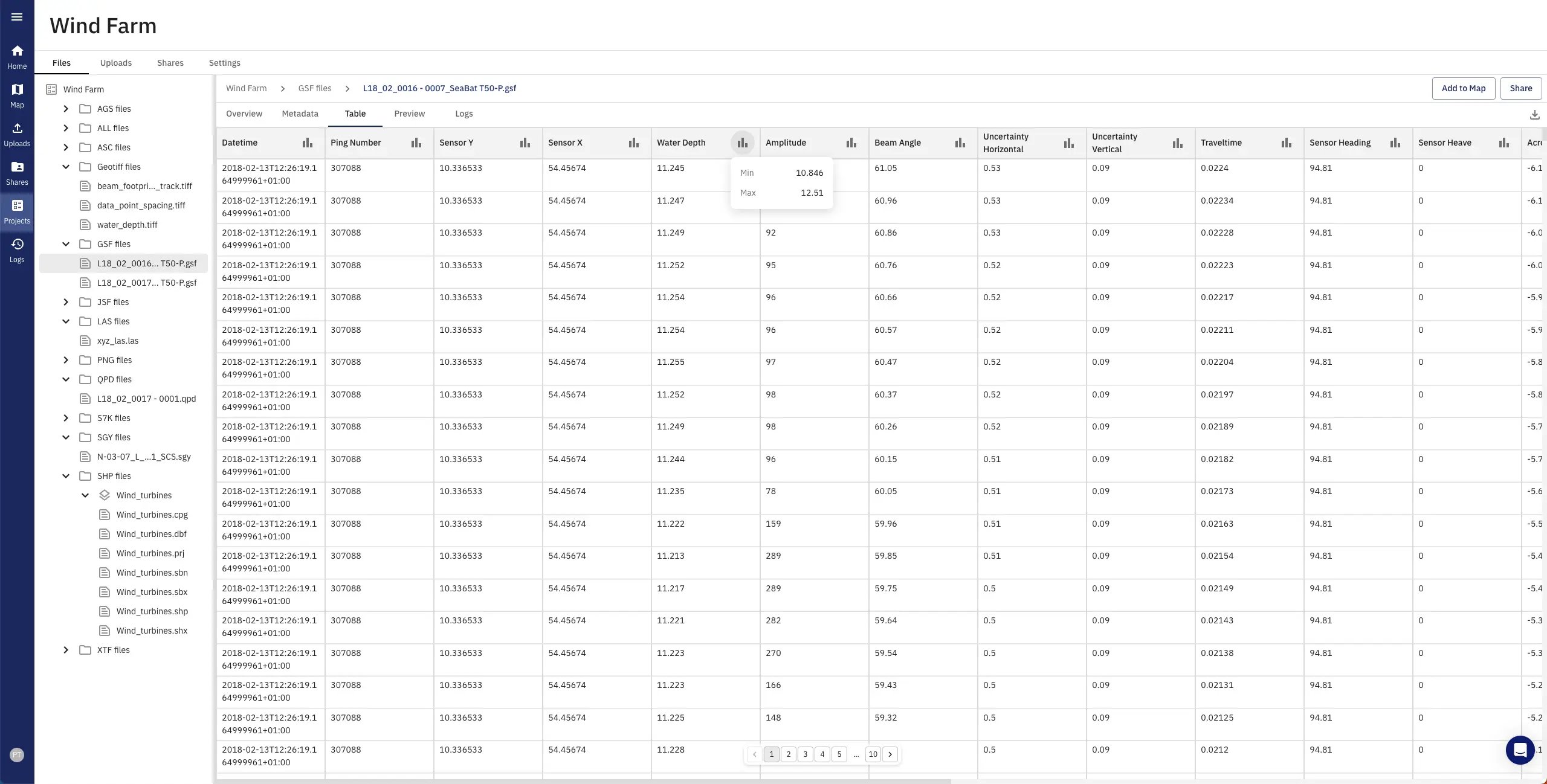
Incorporation of all common file formats in the raster, vector, and point cloud area for example GeoTiff, ALL, GSF, RAW, S7K, LAS/ LAZ, AGS, SGY. Scalable provision of standardised interfaces REST, WMS/WFS etc.
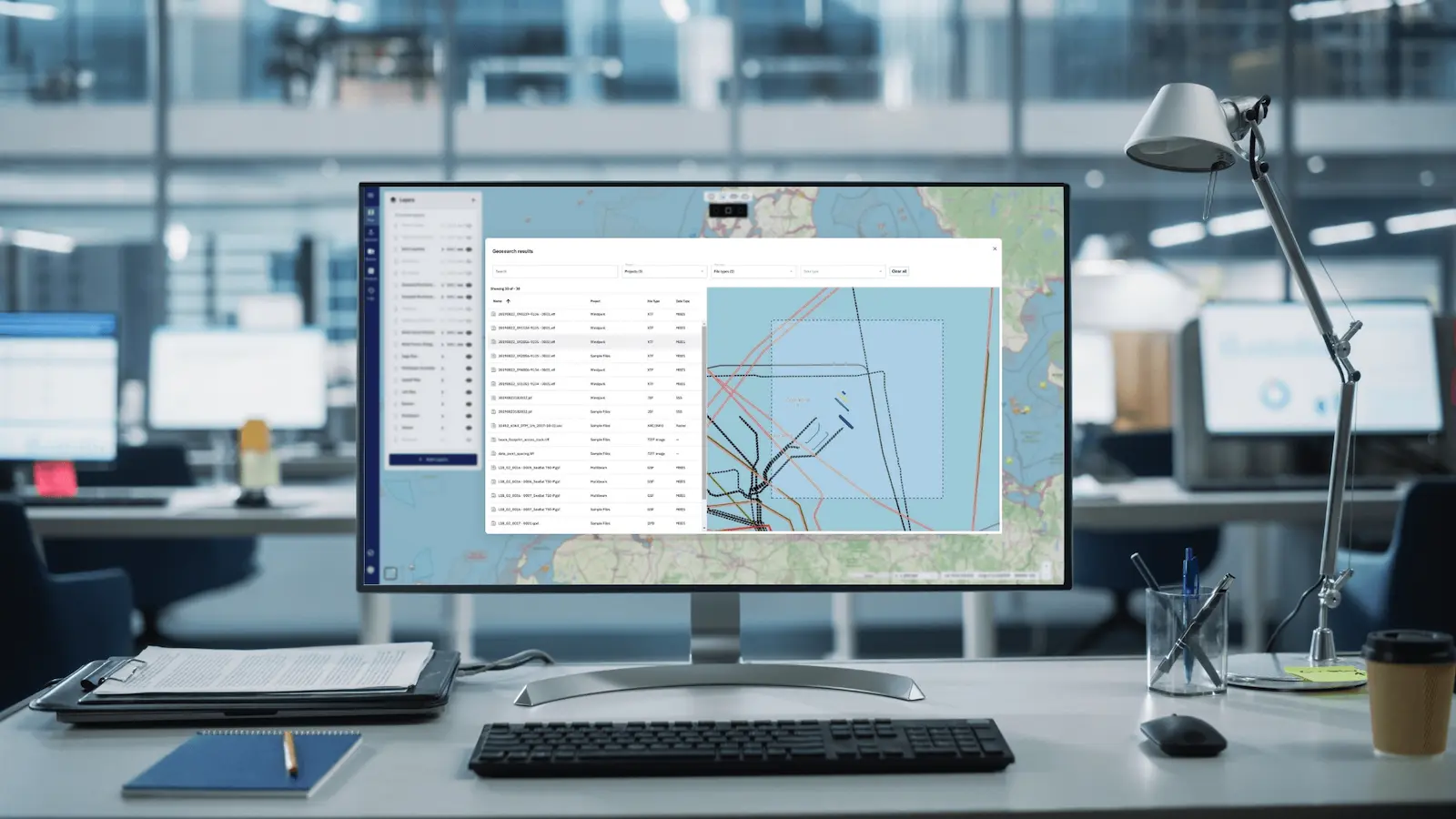
TrueOcean Introduces a New Paradigm with Smart Geospatial Search
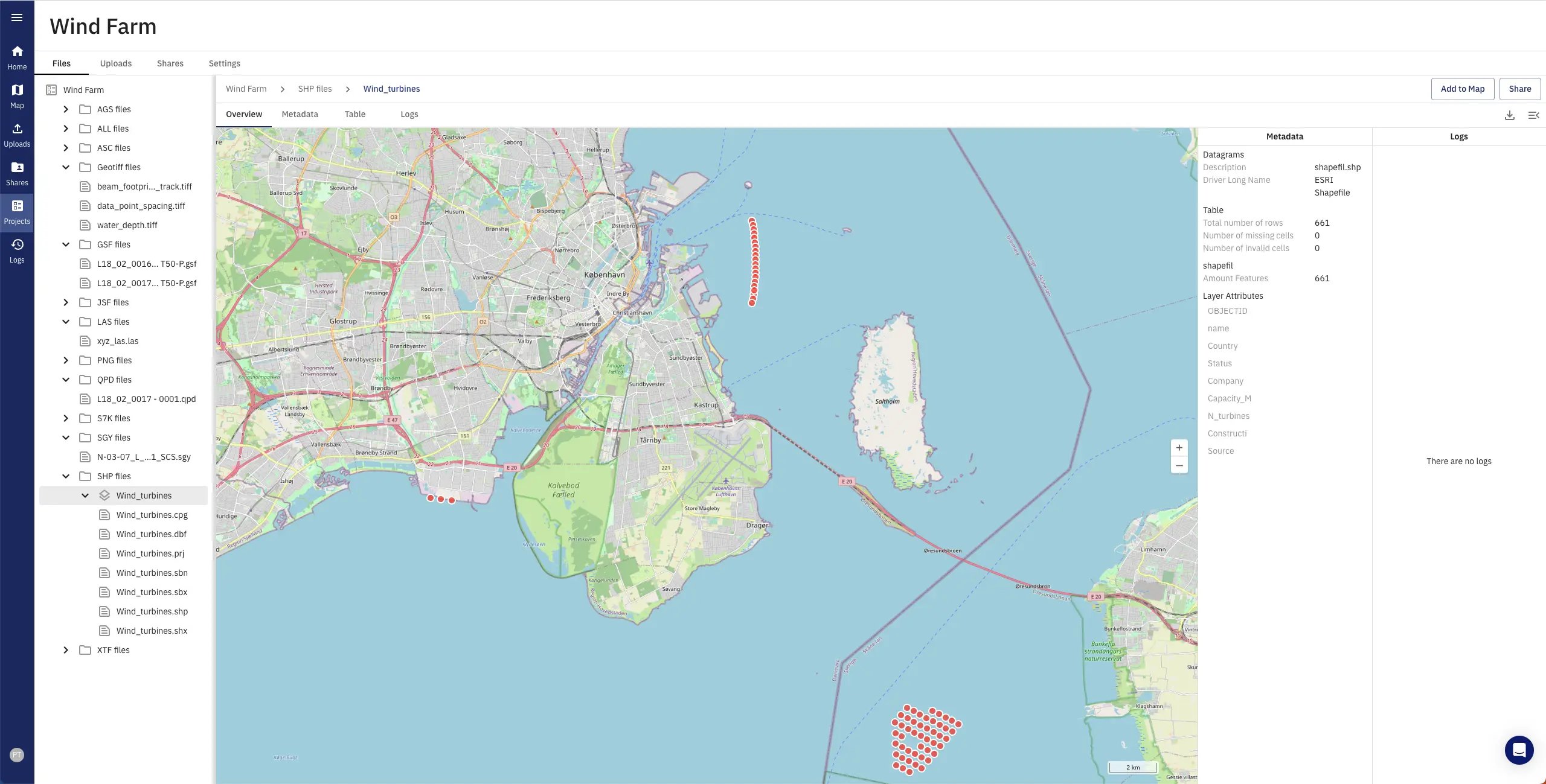
The new geospatial search function enables data on the platform to be located and accessed in seconds using a map-based interface.
White paper: The Race from Ping to Cloud
Are you facing challenges in efficiently managing the massive increase in hydrographic and other marine data needed for your offshore wind farms? If so, this is a must-read.

How to Organise Complex Marine Data in Offshore Wind
Learn the significance of data file formats, explore marine surveys, and discuss underwater sensor data and non-sensor data file formats.













